| Lesson 10 | Problems with many-to-many Relationships |
| Objective | Describe the problems caused by many-to-many relationships and the symptoms that reveal them. |
Problems with Many-to-Many (M:N) Relationships
Conceptually, a many-to-many (M:N) relationship is any case where one instance of A can relate to many B, and one instance of B can relate to many A. In physical relational design, modeling an M:N directly (e.g., by stuffing lists into columns or duplicating rows) leads to redundancy, anomalies, and integrity drift. This lesson explains what breaks, how to spot the problems, and why an associative entity (junction table) is required (the “how” is covered next).
Examples: Students ↔ Classes, Orders ↔ Products, Employees ↔ Projects, Authors ↔ Publications.
What goes wrong if you model M:N directly?
- Redundancy & inconsistency: The same business fact (e.g., a class name or product name) is repeated across many rows. Any change (rename, reprice) must be applied everywhere, or the database contradicts itself.
- Update anomaly: Editing a value in one place doesn’t automatically update its duplicates elsewhere. Result: conflicting copies of the “same” fact.
- Insertion anomaly: You can’t record a new class or product until it appears in a student’s enrollment or an order, forcing fake rows or NULL-ridden placeholders.
- Deletion anomaly: Deleting the last enrollment/order that references a class/product can accidentally delete the only remaining copy of that class/product’s information.
-
Ambiguous “relationship attributes”:
Facts like
Quantity,UnitPriceAtOrder,EnrolledOn,Rolebelong to the pairing (A with B), not to either entity alone. Without a place to put them, designs either duplicate or misplace these values. - Integrity hard to enforce: Foreign keys, uniqueness across pairs, and cascades are awkward (or impossible) without a proper intersection keyed by both sides.
-
Complex, slow queries:
Workarounds (arrays/CSV in a column, repeating columns like
Class1..ClassN, or duplicated entity rows) force scans, string parsing, or unions that don’t scale.
Student–Class, seen in the data
The figure below shows a Students table that attempts to embed class membership by repeating class identifiers and names in student rows. This design looks convenient but guarantees redundancy and anomalies.
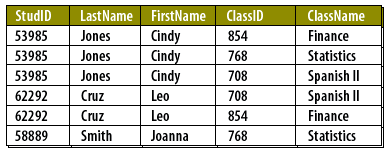
| StudID | LastName | FirstName | ClassID | ClassName |
| -----: | -------- | --------- | ------: | ---------- |
| 53985 | Jones | Cindy | 854 | Finance |
| 53985 | Jones | Cindy | 768 | Statistics |
| 53985 | Jones | Cindy | 708 | Spanish II |
| 62292 | Cruz | Leo | 708 | Spanish II |
| 62292 | Cruz | Leo | 854 | Finance |
| 58889 | Smith | Joanna | 768 | Statistics |
ClassID and ClassName values.
Notice the duplicate values in ClassID and the repetitive ClassName. In a real university, thousands of students taking multiple courses would explode this redundancy[1].
Now change “Spanish I” to “Introductory Spanish.” You must update every occurrence in Students in addition to the authoritative entry in Classes. Miss even one row and the database disagrees with itself.
Insert/delete operations are also brittle: you can’t add a new class until a student “uses” it (insertion anomaly), and removing a student’s last row for a class can erase the only remaining facts about that class (deletion anomaly).
Relational Database Design
How to spot an M:N problem early
- Requirement language: Both sides are plural (“many employees” / “many projects”).
- Data smells: CSV lists in a single column; Class1, Class2… style repeating columns; duplicated entity rows just to store more related items.
- Homeless attributes: You discover values (e.g.,
Quantity,AssignedHours) that clearly describe the pair of entities, not either one alone. - Notation cues: Crow’s Foot shows a foot on both ends; UML multiplicities read
0..*↔0..*.
Why the fix is an associative entity (preview)
The relational model doesn’t implement M:N directly. The remedy is an associative (intersection, junction) entity that:
- Holds a composite key from both sides (or a surrogate key with a uniqueness constraint on the pair).
- Owns relationship attributes (e.g.,
Quantity,UnitPriceAtOrder,EnrolledOn,Role). - Enables clean foreign keys, cascades, indexing, and performant joins.
The next lesson shows the transformation step-by-step.
Operational guardrails (even before refactoring)
- Prefer atomic columns: no lists/arrays/JSON blobs for core relationships.
- Protect entity facts: keep authoritative attributes (e.g., class name) in their own entity; avoid copying them into “child” rows.
- Use constraints: enforce uniqueness on relationship pairs once the junction exists; use ON DELETE/ON UPDATE actions deliberately.
- Index for joins: foreign keys in the associative entity should be indexed to keep queries fast.
Summary: Modeling an M:N directly produces redundancy and the classic insert/update/delete anomalies, invites integrity drift, and slows queries. Recognize the symptoms early and plan for an associative entity to capture the pairing and its attributes. Next, we will resolve M:N into two 1:N relationships cleanly.