| Lesson 4 | Characteristics of Database Tables |
| Objective | Describe the characteristics of relational tables and how they map to implementation in an RDBMS. |
Characteristics of Database Tables in a Relational DBMS
Mouse over the highlighted terms below for definitions.
A relational database is a collection of tables. Each table has two parts: a heading that defines the table name and column names, and a body that holds the rows of data. Columns store attributes - the properties of the entity the table represents. Rows store records, each of which is an instance of that entity. In relational theory, a row is called a tuple, and the table itself is called a relation.
Understanding the distinction between the relational theory vocabulary - relation, tuple, attribute - and the practical vocabulary - table, row, column - is important because both sets of terms appear in database documentation, textbooks, and RDBMS tools. They refer to the same underlying structures from different perspectives, as discussed in Lesson 3.
Design vs. Implementation
During the logical design phase of the DBLC, entities in an ER diagram are represented as relations using relational notation. When the design moves to the implementation phase, the RDBMS creates a physical table corresponding to each relation. The mapping from logical design to physical implementation should be consistent: table names, column names, data types, primary keys, and foreign keys should all carry directly from the relational notation into the CREATE TABLE statement.
A key design principle is integrity by default: constraints should be defined in the database schema so that the RDBMS rejects invalid data at write-time. Relying on application code to enforce data validity after the fact is fragile - a second application accessing the same database may not apply the same rules. Constraints defined in the schema apply universally, regardless of how or where the data is written.
- Design to implementation: An ERD defines a relation; the RDBMS implements it as a physical table with the same structure.
- Integrity by default: Use NOT NULL, CHECK, UNIQUE, and FK constraints to keep data valid at write-time rather than relying on application code after the fact.
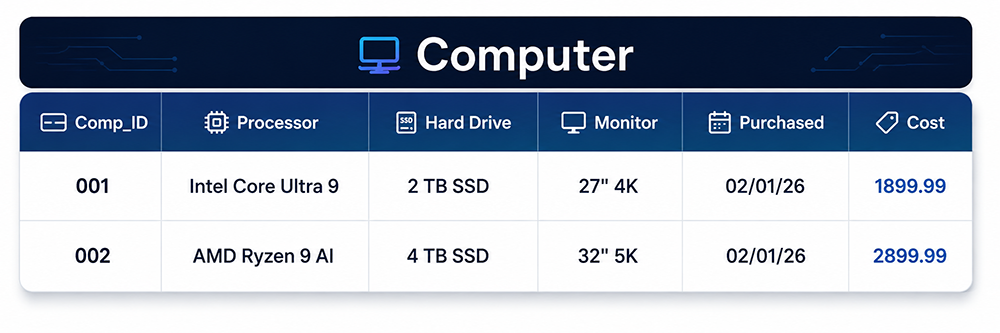
Table Essentials
Keys
Keys are the mechanism by which rows in a table are identified and linked to rows in other tables. Three types of keys are relevant to table design:
- Primary Key (PK) - uniquely identifies each row in the table. A primary key must be unique across all rows and cannot contain a null value. When choosing a primary key, prefer stable, minimal keys - values that are unlikely to change over the life of the record and that use as few columns as necessary. A surrogate key (a system-generated integer such as an auto-increment ID) is often preferred over a natural key when natural key values are subject to change.
-
Foreign Key (FK) - a column in one table that references the primary key (or a
unique key) in another table. Foreign keys enforce referential integrity: the RDBMS will reject any
attempt to insert a foreign key value that does not exist in the referenced table, or to delete a
parent row that is still referenced by child rows. Pair foreign key definitions with
ON DELETEandON UPDATErules that match the intended business semantics (CASCADE, SET NULL, or RESTRICT). - Candidate and Alternate Keys - a candidate key is any column or combination of columns that could serve as the primary key. When one candidate key is designated as the primary key, the remaining candidates become alternate keys. Alternate keys should be enforced with UNIQUE constraints to prevent duplicate values even though they are not the designated primary key.
Data Types
Each column in a table has a data type that constrains the values it can hold. Choosing appropriate data types is part of physical design and has implications for both data integrity and storage efficiency.
- Use
DATEorTIMESTAMPcolumns rather than strings for date and time values. Storing dates as strings makes range queries fragile and prevents the RDBMS from enforcing valid date formats. - Use numeric types (
INT,DECIMAL) rather than strings for quantities, prices, and counts. Numeric types allow arithmetic operations and range comparisons that are not possible on string representations of numbers. - Use CHECK constraints to restrict column values to valid ranges, sets, or formats. For example, a CHECK constraint can ensure that a product price is always positive, or that a status column contains only the values 'active', 'inactive', or 'pending'.
Nullability
A null value in a relational database represents the absence of a known value - it is not zero, not an empty string, and not a placeholder. Null values require careful handling because comparisons involving null produce a third logical state (unknown) rather than true or false.
Allow null values only in columns where the absence of data is semantically meaningful - for example,
a DateTerminated column for an employee who is still active. For all other columns, enforce
NOT NULL to guarantee that critical data is always present. A common source of data quality
problems is columns left nullable by default when they should always contain a value.
Normalization
Normalization is the process of organizing a relational schema to minimize data redundancy and eliminate update, delete, and insert anomalies. The standard normal forms provide a systematic approach:
- First Normal Form (1NF) - each column contains atomic (indivisible) values; no repeating groups.
- Second Normal Form (2NF) - satisfies 1NF and every non-key attribute is fully dependent on the entire primary key (relevant when the primary key is composite).
- Third Normal Form (3NF) - satisfies 2NF and no non-key attribute is transitively dependent on the primary key through another non-key attribute.
- Boyce-Codd Normal Form (BCNF) - a stricter version of 3NF that handles certain edge cases involving overlapping candidate keys.
Design to 3NF or BCNF as a default. Denormalize only when there is a measured, documented performance requirement that normalization cannot satisfy - and document the denormalization explicitly so future maintainers understand why the schema departs from the normal form standard.
Base Tables vs. Virtual Tables
Not all tables in a relational database are stored on disk. The distinction between base tables and virtual tables is fundamental to understanding how a relational database is organized.
A base table is a physical table persisted on disk. Its rows are stored in the database and occupy storage space. When you execute an INSERT, UPDATE, or DELETE statement, you are modifying the data in a base table. Base tables are the primary source of data in the relational model.
A virtual table, most commonly implemented as a view, is derived at query time. A view stores only its definition - a SELECT statement - and produces its result set by executing that query against the underlying base tables each time the view is referenced. The data displayed by a view is not stored separately; it is computed on demand.
Views serve three important purposes in a well-designed database:
- Encapsulation - a view can combine data from multiple base tables using joins and filters, presenting a simplified interface to application developers who do not need to understand the underlying table structure.
- Access control - a view can enforce data access policies by exposing only the columns and rows that a particular user role should see. A finance view might include cost and pricing columns; a support view might show only configuration attributes.
- Stability - a view provides a stable interface to applications. If the underlying base tables are restructured - columns renamed, tables split or merged - the view definition can be updated to preserve the interface that applications depend on, without requiring changes to the application code.
Worked Example: Computer Inventory
The Computer table illustrates the characteristics described in this lesson. In relational notation:
Computer (Comp_ID, Processor, HardDrive, Monitor, Purchased, Cost)
The table has one relation name (Computer), one primary key (Comp_ID), and five non-key attributes. Each row represents a single computer instance. The following sample data demonstrates the structure:
| Comp_ID | Processor | Hard Drive | Monitor | Purchased | Cost |
|---|---|---|---|---|---|
| 001 | Intel Core Ultra 9 | 2 TB SSD | 27" 4K | 2026-02-01 | 1899.99 |
| 002 | AMD Ryzen 9 AI | 4 TB SSD | 32" 5K | 2026-02-01 | 2899.99 |
Applying the concepts from this lesson to this table:
- Computer is the table name (relation name).
- Comp_ID is a candidate key; it is designated as the primary key because it uniquely identifies each computer record and is stable over the life of the record.
- Each row represents one instance of the Computer entity.
- Purchased should be defined as a
DATEtype, not a string, to support date range queries and enforce valid date formats. - Cost should be defined as
DECIMAL(10,2)to support accurate financial calculations and prevent rounding errors. - A NOT NULL constraint on Processor, HardDrive, and Monitor ensures that every computer record is complete.
Access, Views, and Performance
Once a table is defined and populated, how it is accessed and maintained affects both performance and data quality over the operational life of the database.
- Multiple Views. Define separate views for different user roles. A finance view of the Computer table might include Comp_ID, Purchased, and Cost. A support view might include Comp_ID, Processor, HardDrive, and Monitor. Each role sees exactly the data it needs without being exposed to columns it should not access.
- Indexes. Create indexes on primary key columns (most RDBMS systems do this automatically), foreign key columns, and any columns frequently used in WHERE clause predicates. Avoid creating indexes on every column - each index consumes storage and adds overhead to INSERT, UPDATE, and DELETE operations. Over-indexing write-heavy tables can degrade write performance significantly.
- Constraints before code. Let the database enforce data validity through constraints rather than application logic. A NOT NULL constraint applied in the schema prevents null values regardless of which application writes to the table. A CHECK constraint on Cost prevents negative prices at the database level. This approach is more reliable than application- level validation because it applies universally and cannot be bypassed by a direct database connection.
Key Terms
Mouse over each term for its definition:
- Relation
- Attribute
- Tuple
- RDBMS
- Primary Key
- Foreign Key
- View
- CHECK Constraint
- Normalization
Relational Table Characteristics - Quiz
Test your understanding of relational table characteristics before moving to the next lesson:
Relational Table Characteristics - Quiz