| Lesson 10 | Vertical Partitioning |
| Objective | Describe the characteristics of Vertical Partitioning |
Database Vertical Partitioning
Vertical partitioning is a database design technique where a table is divided into multiple physical segments based on groups of columns rather than rows. Unlike horizontal partitioning—which distributes tuples across partitions—vertical partitioning reorganizes attributes so that frequently accessed columns are stored together. When used correctly, vertical partitioning improves performance, storage efficiency, and data management, especially in modern systems such as Oracle Database 23ai, PostgreSQL with declarative partitioning, SQL Server 2022, and columnar HTAP engines.
1. Column-Based Fragmentation
In vertical partitioning, each fragment contains a subset of attributes from the original table. These fragments share the same primary key, allowing the database engine to reassemble the full record when needed. By grouping attributes according to access patterns, the storage layout more closely aligns with actual workload requirements.
2. Reduced I/O Through Column-Level Access
Most queries request only a portion of a table’s columns. With vertical partitioning, queries that need just a small set of attributes read fewer pages from disk or buffer cache. This process—often referred to as column pruning or projection pushdown—lowers I/O, speeds scans, and reduces memory pressure. Modern optimizers (e.g., Oracle's projection pruning and PostgreSQL's columnar extensions) take advantage of this automatically.
3. Improved Storage Efficiency and Compression
Because each partition groups columns of similar data types, more effective compression algorithms can be applied. Column stores and hybrid systems regularly compress homogeneous column groups at much higher ratios than row stores. Vertical partitioning enables similar efficiencies in row-store databases by physically colocating similar attributes.
4. Enhanced Manageability and Lifecycle Operations
Working with smaller, attribute-specific fragments simplifies maintenance operations:
- Indexes are smaller and more targeted
- Backups can operate on column groups rather than entire tables
- Schema evolution becomes easier; new attributes can be isolated in separate partitions
- Archival strategies can differ per fragment (e.g., infrequently used attributes stored on slower storage)
This is especially useful in enterprise environments where hot, warm, and cold data are stored across different classes of hardware.
5. Support for Distributed and Multi-Site Architectures
In multi-site or distributed database environments, vertical fragments can be allocated to different locations based on access patterns. Highly accessed attributes may reside at edge nodes or faster tiers, while infrequently accessed attributes may be stored centrally or on lower-cost infrastructure. Oracle Sharding, PostgreSQL Citus, and SQL Server Distributed Partition Views can all leverage attribute-fragment allocation strategies.
6. Alignment With Transaction Requirements
The effectiveness of vertical partitioning depends on how well the fragments match transaction workloads. Ideally, each workload interacts with only one fragment, minimizing joins and reducing disk access. When transaction patterns are well understood—such as frequently accessed dimension attributes or primary descriptive fields—vertical partitioning delivers substantial performance gains.
7. Systematic Approach for Real-World Designs
Most real-world tables contain dozens of attributes, some of which are accessed together and others that are rarely touched. Automated or semi-automated attribute clustering tools (workload analyzers, heat maps, execution statistics) can help determine optimal grouping. Modern RDBMS tools can analyze query history to recommend vertical fragmentation strategies.
Example of Vertical Partitioning
Consider the following unpartitioned CD table:
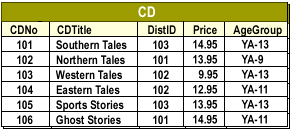
| CDNo | CDTitle | DistID | Price | AgeGroup |
| ---- | -------------- | ------ | ----- | -------- |
| 101 | Southern Tales | 103 | 14.95 | YA-13 |
| 102 | Northern Tales | 101 | 13.95 | YA-9 |
| 103 | Western Tales | 102 | 9.95 | YA-13 |
| 104 | Eastern Tales | 102 | 12.95 | YA-11 |
| 105 | Sports Stories | 103 | 13.95 | YA-11 |
| 106 | Ghost Stories | 101 | 14.95 | YA-11 |
If application usage shows that users frequently access CDTitle and DistID together, but rarely access Price and AgeGroup, a vertical partitioning strategy would divide the table into two fragments: one containing descriptive and distributor information, the other containing pricing information.
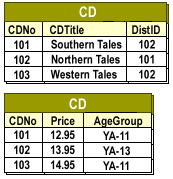
| CDNo | CDTitle | DistID |
| ---- | -------------- | ------ |
| 101 | Southern Tales | 102 |
| 102 | Northern Tales | 101 |
| 103 | Western Tales | 102 |
Table 2: CD
| CDNo | Price | AgeGroup |
| ---- | ----- | -------- |
| 101 | 12.95 | YA-11 |
| 102 | 13.95 | YA-13 |
| 103 | 14.95 | YA-11 |
CD Table 1: Title and DistID; CD Table 2: Price and AgeGroup
Because both fragments share the key CDNo, they can be recombined through a join when complete records are required. However, most OLTP transactions would access only one fragment, maximizing performance.
Conclusion
Vertical partitioning is a powerful design strategy that optimizes the layout of database attributes to match real-world access patterns. By reducing I/O, improving compression, supporting distributed layouts, and simplifying maintenance, vertical partitioning remains highly relevant in modern database platforms. Its success depends on careful workload analysis, proper grouping of attributes, and alignment with long-term transactional requirements.