| Lesson 7 | Relationships and referential integrity |
| Objective | Describe mistakes associated with relationships and referential integrity. |
Referential Integrity Relationships
Mistakes associated with Database Relationships
The most significant advantage of using an RDBMS is the ability to link tables through
primary and foreign keys and then create table joins based on those links to retrieve meaningful information. By linking the CD and Distributor tables in the project database, for instance, you enable users to list the title of a CD next to the name of its distributor.
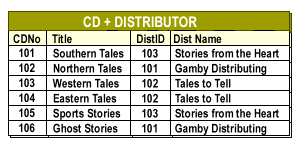
Creating relationships between tables also enables you to enforce referential integrity-- to ensure a change in one table does not make table data inconsistent (such as by removing a record from a table on the one side of a one-to-many relationship when there are related records in the table on the many side), and to automatically update changes in one table in related tables.
Common mistakes associated with relationships and referential integrity include:
- Creating too many relationships
- Adding unnecessary foreign keys
- Needlessly enforcing referential integrity
Too many relationships
In the project database, there is absolutely no reason to create a relationship between the Category and Distributor tables.
Even so, the temptation to insert the CategoryID field into the Distributor table as a foreign key is too much for some designers to resist.
The two tables have nothing to do with each other and, if you need to have information about a CD's category and distributor in the same view, you can create a new table based on the CD table's link to the Category table and the CD table's link to the Distributor table.
The two tables have nothing to do with each other and, if you need to have information about a CD's category and distributor in the same view, you can create a new table based on the CD table's link to the Category table and the CD table's link to the Distributor table.
Unnecessary fields
When you create a one-to-many relationship, you only need to insert the primary key of the table on the "one" side into the table on the "many" side as a foreign key. You don't need to insert the "many" table's primary key into the "one" table as a foreign key to "complete the circuit." It works just fine going in one direction.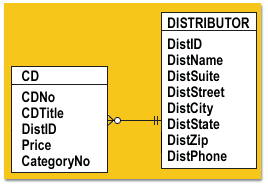
Needlessly enforcing referential integrity
Just because two tables are related is not sufficient reason to enforce referential integrity between them. Just as in creating an index, enforcing referential integrity between tables takes time,
especially when the tables are large, so you should choose when to do so carefully. If Stories on CD had a business rule stating it would only list a distributor if they had ordered a CD from them,
then it would make sense to enforce referential integrity between the CD and Distributor tables. Then users would be prevented from entering distributors who did not offer a product Stories on CD
ordered. If no such rule were in place, it would not be appropriate to enforce referential integrity between the tables as users could enter potential distributors into the Distributor table, regardless of whether Stories on CD had placed an order with them.
Insufficient Normalization
Though too much normalization can make the database slower than necessary, poor performance is rarely the reason a software project fails. Much more common reasons for failure are designs that are too complex and confusing to build, and designs that don’t do what they’re supposed to do. A database that doesn’t ensure the data’s integrity definitely doesn’t do what it’s supposed to do.
Normalization is one of the most powerful tools you have for protecting the data against errors. If the database refuses to allow you to make a mistake, you won’t have trouble with bad data later. Adding an extra level of indirection to gather data from a separate table adds only milliseconds to most queries. It is very hard to justify allowing inconsistent data to enter the database to save one or two seconds per user per day.
This does not mean you need to put every table in Fifth Normal Form, but there’s no excuse for tables that are not in at least Third Normal Form. It’s way too easy to normalize tables to that level for anyone to claim that it is not necessary.
If the code needs to parse data from a single field (Hobbies = "sail boarding, skydiving, knitting"), break it into multiple fields or split its values into a new table. If a table contains fields with very similar names (JanPayment, FebPayment, MarPayment), pull the data into a new table. If two rows might contain identical values, figure out what makes them logically different and add that explicitly to the table so you can make a primary key. If some fields’ values don’t depend on the entire key, consider spreading the record across multiple tables.
The next lesson describes mistakes associated with international issues.
Normalization is one of the most powerful tools you have for protecting the data against errors. If the database refuses to allow you to make a mistake, you won’t have trouble with bad data later. Adding an extra level of indirection to gather data from a separate table adds only milliseconds to most queries. It is very hard to justify allowing inconsistent data to enter the database to save one or two seconds per user per day.
This does not mean you need to put every table in Fifth Normal Form, but there’s no excuse for tables that are not in at least Third Normal Form. It’s way too easy to normalize tables to that level for anyone to claim that it is not necessary.
If the code needs to parse data from a single field (Hobbies = "sail boarding, skydiving, knitting"), break it into multiple fields or split its values into a new table. If a table contains fields with very similar names (JanPayment, FebPayment, MarPayment), pull the data into a new table. If two rows might contain identical values, figure out what makes them logically different and add that explicitly to the table so you can make a primary key. If some fields’ values don’t depend on the entire key, consider spreading the record across multiple tables.