Table columns are the structural units of a relational database. Every piece of data stored in a
relational database is stored in a column, and the design of those columns - their names, data types,
constraints, and relationships - determines how reliably the database stores, retrieves, and protects
that data. The following nine rules govern the creation and maintenance of table columns in a
well-designed relational database.
Naming Conventions. Use clear, concise, and meaningful names for table columns.
Column names should communicate the attribute they represent without requiring external documentation.
Avoid spaces, special characters, and reserved SQL keywords in column names. Use underscores to
separate words in multi-word names, and follow a consistent naming pattern throughout the schema.
snake_case (e.g. last_name, purchase_date) is widely
preferred in RDBMS environments because it is unambiguous and compatible with all major database
platforms. Inconsistent naming across tables - mixing CustID in one table with
customer_id in another - creates confusion during queries and maintenance.
Data Types. Assign the data type that most accurately represents the nature of the
data the column will store. Common data types include INTEGER and BIGINT
for whole numbers, DECIMAL and NUMERIC for precise fractional values
such as prices, VARCHAR and CHAR for text, and DATE and
TIMESTAMP for temporal values. Choose types that reflect domain meaning rather than
convenience - storing a date as a VARCHAR may seem easier but prevents date arithmetic,
range queries, and format validation. Choose the smallest type that accommodates the full range of
expected values to minimize storage requirements and improve performance.
Null Values. Explicitly determine whether each column may contain null values. A
null value represents the absence of a known value - it is not zero, not an empty string, and not
a default. Allow nulls only in columns where the absence of data is semantically meaningful, such
as a DateTerminated column for an employee who is still active. For all other columns,
apply NOT NULL to ensure that critical attributes are always present. Leaving columns
nullable by default is a common source of data quality problems that are difficult to correct after
data has accumulated.
Primary Keys. Designate one or more columns as the primary key to uniquely identify
each row in the table. Primary keys must be unique across all rows and cannot contain null values.
Choose primary keys that are stable - values unlikely to change over the life of the record - and
minimal, using as few columns as necessary. A surrogate key (a system-generated integer such as an
auto-increment ID) is often preferred over a natural key when natural key values are subject to
change. Primary keys are essential for maintaining data consistency and supporting efficient
retrieval and modification of records.
Foreign Keys. When a column contains values that reference rows in another table,
define it as a foreign key. Foreign keys establish relationships between tables, enforce referential
integrity, and enable efficient multi-table queries. A foreign key constraint tells the RDBMS that
the value in this column must exist as a primary key (or unique key) value in the referenced table.
Pair foreign key definitions with ON DELETE and ON UPDATE rules that
reflect the intended business behavior - CASCADE, SET NULL, or RESTRICT - so that the database
handles related data correctly when parent rows change.
Default Values. Assign default values to columns where a standard value applies
when no explicit value is provided. Default values are automatically inserted when a new record is
added without specifying a value for that column. For example, a Status column might
default to 'active', or a CreatedDate column might default to
CURRENT_TIMESTAMP. Default values maintain data consistency, reduce the need for
application-level logic to populate common values, and decrease the likelihood of unintended nulls
in columns that should always have data.
Column Constraints. Use constraints to enforce rules on the data stored in a
column beyond what the data type alone can express. UNIQUE prevents duplicate values
in a column while permitting nulls. CHECK enforces a boolean condition on column
values - for example, requiring that a price column always contain a positive value. NOT
NULL prevents missing values. Constraints defined in the schema apply universally to all
data written to the table, regardless of which application or user performs the write. This makes
constraint-based validation more reliable than application-level validation alone.
Indexing. Create indexes on columns that are frequently used in WHERE clause
predicates, JOIN conditions, or ORDER BY clauses. Indexes allow the RDBMS to locate rows matching
a query condition without scanning the entire table, which dramatically improves query performance
on large tables. Most RDBMS systems automatically create an index on the primary key column. Create
additional indexes on foreign key columns and on any columns frequently used to filter or sort
results. Use indexes judiciously - each index consumes additional storage and adds overhead to
INSERT, UPDATE, and DELETE operations. Over-indexing write-heavy tables can degrade write
performance significantly.
Comments and Documentation. Document each column with a description of its purpose,
the constraints that apply to it, and any relationships to other tables. Most RDBMS platforms support
column-level comments that are stored in the data dictionary alongside the schema definition. This
documentation is invaluable during database maintenance, troubleshooting, onboarding of new team
members, and future development. A column named status_cd with no documentation is
ambiguous; a column with a comment explaining that it stores a two-character ISO status code
referencing the status_lookup table is unambiguous.
Applying these nine rules consistently produces a schema whose columns are self-describing, reliably
constrained, and efficient to query. Well-designed columns reduce the burden on application code,
prevent data quality problems at the source, and support the long-term maintainability of the database.
Columns Store Attributes of the Entity
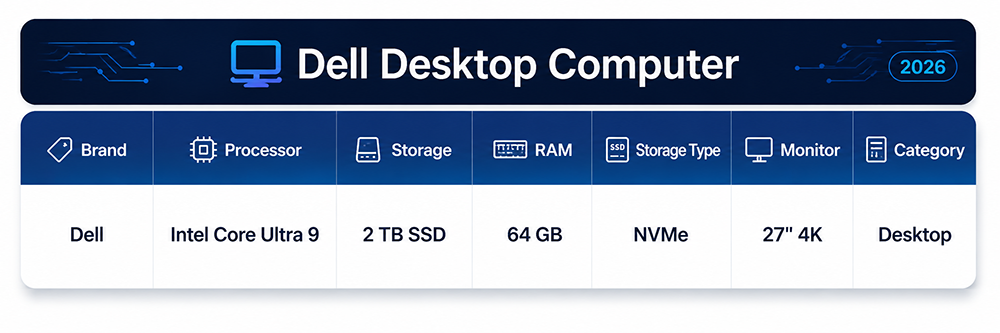
When you create a table, you use its columns to store the attributes of the entity the table represents.
A computer entity, for example, has attributes that describe its hardware configuration: brand,
processor, storage capacity, RAM, storage type, monitor size, and category. Each of those attributes
becomes a column in the Computer table.
Brand
Processor
Storage
RAM
Storage Type
Monitor
Category
Dell
Intel Core Ultra 9
2 TB SSD
64 GB
NVMe
27" 4K
Desktop
In relational notation this table is expressed as:
Each column name is distinct, each stores values of a single type, and together they describe every
relevant attribute of the Computer entity. The CompID column serves as the primary key,
uniquely identifying each computer record.
Two Fundamental Rules for Table Columns
Beyond the nine design rules above, every column in a relational table must satisfy two fundamental
structural rules:
The column must have a unique name within the table. Every column must represent
a different attribute of the entity the table describes. No two columns in the same table can share
a name. This rule is not merely a convention - it is a requirement of the relational model. If the
same attribute name appears in more than one table, that shared attribute typically indicates a
relationship[2] between those tables rather than a
duplication error within a single table.
The values for the column must come from a single
domain[1]. All values stored in a column
must be of the same type and represent the same kind of data. A column defined to store processor
names should not also store monitor sizes or purchase dates. The domain of a column defines the
set of valid values for that attribute. Domain constraints are covered in detail in a later lesson.
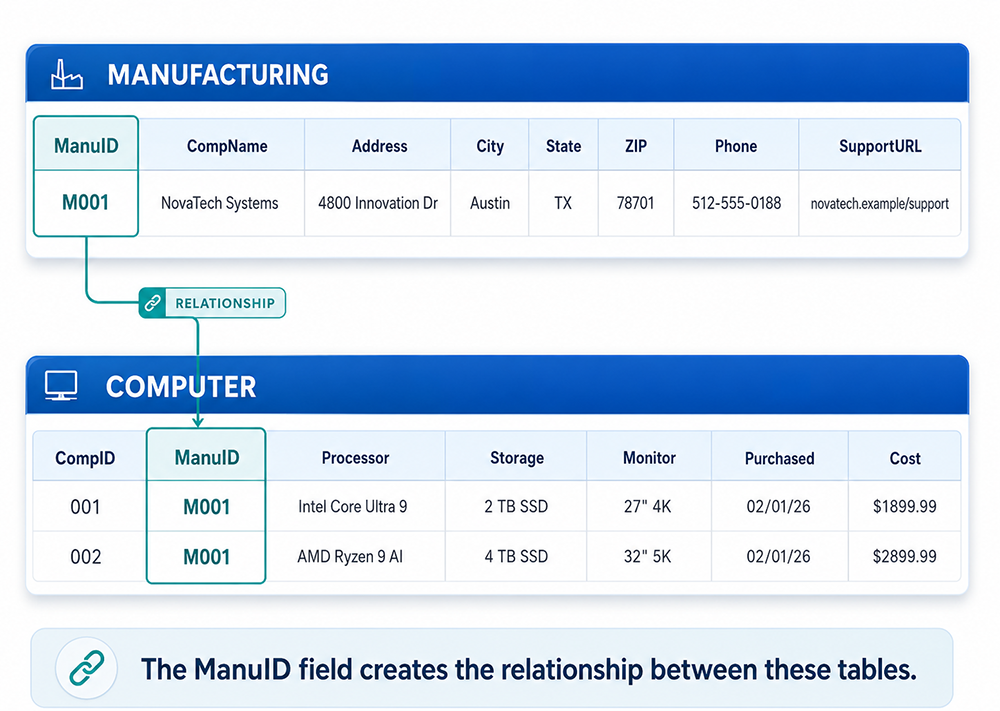
Imagine that your database contains two tables: one listing computer manufacturers (the MANUFACTURING
table) and another listing computers owned by your organization (the COMPUTER table). Both tables
contain the ManuID column.
The ManuID field creates the relationship between these tables.
ManuID is the primary key in the MANUFACTURING table and the foreign key in the COMPUTER table.
Shared Columns Create Relationships Between Tables
The presence of ManuID in both the MANUFACTURING table and the COMPUTER table is not a
violation of the unique name rule - it is the mechanism by which the two tables are related. In the
MANUFACTURING table, ManuID is the primary key that uniquely identifies each manufacturer.
In the COMPUTER table, ManuID is a foreign key that references the primary key of the
MANUFACTURING table.
Establishing this relationship enables you to link the two tables in a query. If a computer develops
a fault and you need to contact its manufacturer, you look up the computer's record in the COMPUTER
table, note its ManuID value, and use that value to find the manufacturer's contact
details - including phone number and support URL - in the MANUFACTURING table. A single foreign key
value connects the two records across tables without duplicating the manufacturer's contact information
in every computer record.
The relationship between these tables is a
one-to-many relationship[3]: one manufacturer can be
associated with many computers, but each computer record references exactly one manufacturer. This
cardinality is enforced by the foreign key constraint. If
referential integrity[4] is enforced between the two
tables, the Relational Database Management System[5]
(RDBMS) will reject any attempt to insert a ManuID value in the COMPUTER table that does
not exist in the MANUFACTURING table. It would make no sense to record a computer as manufactured by
an organization that is not in the MANUFACTURING table - and with referential integrity enforced, the
database makes that mistake impossible.
Glossary
[1]Domain: Determines the type of data values that are
permitted for a given attribute. All values in a column must come from the same domain.
[2]Relationship: If the same attribute occurs in more than
one table, a relationship exists between those two tables.
[3]One-to-many relationship (1:N): For one instance of
entity A, there exist zero, one, or many instances of entity B; but for one instance of entity B,
there exists zero or one instance of entity A.
[4]Referential integrity: The means of maintaining the
integrity of data between related tables. A foreign key column value must be null or match a value
in the corresponding primary key column of the referenced table. Usually enforced with foreign key
constraints.
[5]RDBMS (Relational Database Management System): A
software package that manages and provides access to a relational database. These systems follow
Codd's 12 rules of relational databases and use SQL to access and manipulate data.