| Lesson 3 | Indexing |
| Objective | Explain the purpose of creating Indexes |
SQL Indexes for Performance
In earlier modules you focused on logical design: choosing tables, keys, and relationships that represent the business correctly. Physical design adds a new concern: query performance. Indexes are one of the most important physical design tools you have. Used wisely, they can reduce response time from seconds to milliseconds; used carelessly, they can slow data modification and waste storage.
This lesson explains why indexes exist, what problems they solve, and how to choose useful indexes for a relational database.
This lesson explains why indexes exist, what problems they solve, and how to choose useful indexes for a relational database.
Purpose of Indexes in Relational Databases
At a high level, an index is a separate data structure that lets the RDBMS find rows quickly without scanning an entire table. Conceptually, it works like the index at the back of a book:
- The table holds the full rows (all columns).
- The index holds selected column values plus pointers to the corresponding rows.
- Queries use the index to jump directly to relevant rows instead of reading every row.
- Speed up search conditions in
WHEREclauses. - Improve join performance when tables are linked on key columns.
- Support efficient sorting and grouping on frequently used columns.
Data Analysis for DB Design
Heap Storage and the Need for Indexes
By default, many tables are stored as heaps: the RDBMS appends new rows where space is available, without guaranteeing any useful order by business columns such as customer, product, or date. That means the physical order of rows rarely matches the logical access pattern in your queries.
Consider a simplified ORDER table for the Stories on CD example:
Consider a simplified ORDER table for the Stories on CD example:
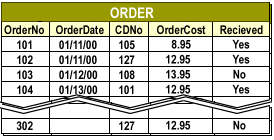
| OrderNo | OrderDate | CDNo | OrderCost | Received | | ------- | --------- | ---- | --------- | -------- | | 101 | 01/11/00 | 105 | 8.95 | Yes | | 102 | 01/11/00 | 127 | 12.95 | Yes | | 103 | 01/12/00 | 108 | 13.95 | No | | 104 | 01/13/00 | 101 | 12.95 | Yes | | 302 | *(blank)* | 127 | 12.95 | No |Order table consisting of columns OrderNo, OrderDate, CDNo, OrderCost, Received.
Suppose users often ask, “Show every order for CD number 101” or “List all orders for CD 127.” In a heap, the RDBMS must examine every row to answer that request, because rows are not stored in
On a small table this cost is negligible. On a table with millions of rows, repeated full scans quickly become a performance problem. Indexes solve this by maintaining a compact, ordered structure keyed by frequently searched columns.
CDNo order.
On a small table this cost is negligible. On a table with millions of rows, repeated full scans quickly become a performance problem. Indexes solve this by maintaining a compact, ordered structure keyed by frequently searched columns.
What an Index Looks Like
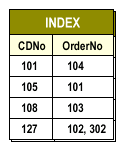
| CDNo | OrderNo | | ---- | -------- | | 101 | 104 | | 105 | 101 | | 108 | 103 | | 127 | 102, 302 |An index consisting of key column CDNo and pointers to matching OrderNo values.
Logically, this index is an ordered list of
When a query filters on
CDNo values and the corresponding orders. Internally, most relational systems implement indexes as balanced trees (for range searches) or specialized structures such as hash indexes or bitmaps for particular workloads.
When a query filters on
CDNo, the optimizer can:
- Seek into the index to find matching keys.
- Follow stored row pointers (or clustered locations) to retrieve only the required rows.
Creating Indexes with SQL
The basic DDL for creating a nonclustered index is:
Example: an index on the
Common patterns across RDBMS platforms:
CREATE [UNIQUE] INDEX index_name
ON table_name (column1, column2, ...);
Example: an index on the
email column in a users table:
CREATE INDEX users_email_idx
ON users (email);
Common patterns across RDBMS platforms:
- Primary key and unique constraints usually create indexes automatically.
- You can add additional indexes to support frequent search, join, and sort operations.
- Some systems support advanced options such as filtered/partial indexes, expression indexes, or different index types (B-tree, bitmap, hash).
Index Types in Practice
While terminology varies slightly between products, most systems support:
- Clustered or index-organized storage The index defines the physical order of rows. When queries match the clustered key or ranges of that key, I/O patterns are very efficient. You typically have one such structure for each table.
- Nonclustered (secondary) indexes
Additional indexes that point into the base storage. These speed specific queries but add maintenance cost on
INSERT,UPDATE, andDELETEoperations. - Composite indexes
Indexes defined on multiple columns, such as
(CustID, OrderDate), which are chosen based on common query patterns.
Best Practices for Choosing Indexes
To use indexes effectively, align them with real queries and business requirements:
- Index search and join predicates
Focus on columns that appear frequently in
WHERE,JOIN,GROUP BY, andORDER BYclauses. Indexing rarely used columns usually adds overhead without measurable benefit. - Prefer selective columns Columns whose values are highly selective (for example, unique or near-unique identifiers) make excellent index keys, because they quickly narrow the result set.
- Keep indexes narrow Avoid including large text or JSON columns in index keys. Narrow keys reduce index size and update cost.
- Use composite keys deliberately
When you define an index on multiple columns, the column order should match typical query predicates, such as
WHERE CustID = ? AND OrderDate > ?. The leftmost columns in the index are the most important for the optimizer. - Consider covering indexes for critical queries A covering index contains all columns a query needs (either as key or included columns, depending on the RDBMS). This lets the optimizer satisfy the query directly from the index structure, avoiding lookups to the base table.
- Balance reads and writes Each additional index makes reads potentially faster but writes more expensive, because the RDBMS must maintain the index on every data change. Highly transactional tables usually require fewer, carefully selected indexes than read-heavy reporting tables.
- Monitor and revisit As applications evolve, queries change. Regularly review index usage reports and execution plans. Remove unused indexes, adjust composite index definitions, and add new ones where you see consistent performance issues.
Trade-offs and Maintenance
Indexes are not “set and forget” structures. Good physical design includes:
The next lesson looks more deeply at how indexing interacts with clustering and partitioning in physical design.
- Ongoing statistics maintenance so the optimizer has accurate information about data distribution.
- Rebuild or reorganization policies as appropriate for the RDBMS when heavy updates fragment index pages.
- Careful review of wide or rarely used indexes, which can be candidates for removal.
The next lesson looks more deeply at how indexing interacts with clustering and partitioning in physical design.