| Lesson 14 | Building the Database |
| Objective | Explain how to use SQL to build a Database |
Building a Database Using Modern SQL
In this lesson, you will learn how relational databases are created using SQL in a modern environment. The process includes defining a schema, creating base tables, applying integrity constraints, and—when needed, creating virtual structures such as views. These foundations are essential for designing reliable, scalable relational systems.
1. Creating a Schema
A schema is a logical container that groups related database objects: tables, views, indexes, sequences, and constraints. In most RDBMS platforms (Oracle, PostgreSQL, SQL Server), the schema is associated with a database user or owner.
The basic SQL syntax to create a new schema is:
CREATE SCHEMA schema_name;
For example:
CREATE SCHEMA dispersednet;
By default, the creator of the schema becomes its owner. To assign ownership to another user, an AUTHORIZATION clause can be included:
CREATE SCHEMA schema_name AUTHORIZATION owner_user_id;
Example:
CREATE SCHEMA distributedNetworks AUTHORIZATION dba;
Many SQL implementations also allow you to create tables and other objects within the same schema block:
CREATE SCHEMA schema_name AUTHORIZATION owner_user_id
{
-- additional CREATE statements
};
2. Creating Base Tables with SQL
A relational database begins with base relations—the physically stored tables that serve as the permanent structures for application data.
The diagram below illustrates a typical CREATE TABLE statement.
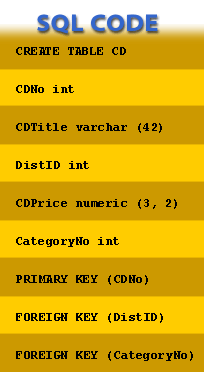
- CREATE TABLE CD: Creates a table named
CD. - CDNo int: Defines a column named
CDNoas an Integer. - CDTitle varchar(42): A text column up to 42 characters.
- DistID int: Distributor ID, Integer.
- CDPrice numeric(3,2): Price with 3 digits and 2 decimals (e.g., 14.95).
- CategoryNo int: Category identifier.
- PRIMARY KEY (CDNo): Defines
CDNoas the primary key. - FOREIGN KEY (DistID): Declares
DistIDas a foreign key. - FOREIGN KEY (CategoryNo): Declares
CategoryNoas a foreign key.
Database Design for Mere Mortals
Using these elements together, a modern, best-practice SQL table definition might look like:
CREATE TABLE CD (
CDNo INT PRIMARY KEY,
CDTitle VARCHAR(42) NOT NULL,
DistID INT NOT NULL,
CDPrice NUMERIC(3,2),
CategoryNo INT,
CONSTRAINT fk_cd_dist
FOREIGN KEY (DistID)
REFERENCES Distributor(DistID),
CONSTRAINT fk_cd_category
FOREIGN KEY (CategoryNo)
REFERENCES Category(CategoryNo)
);
Note: In Oracle 19c/23c, NUMBER(3,2) is equivalent to ANSI NUMERIC(3,2).
For portability, storing IDs as INTEGER and prices as NUMERIC is considered a best practice.
3. Understanding Identifiers
Every database object—schema, table, column, index, constraint—has a unique identifier within its scope. SQL naming rules ensure clarity and prevent ambiguity.
- Database names must be unique per server instance.
- Table and view names must be unique within a schema.
- Columns and constraints must be unique within a table.
Because scopes differ, the same identifier may appear in different schemas or in different tables without conflict.
For example, two tables in different schemas may both be named Order.
4. Base Relations vs. Views
SQL distinguishes between base relations (physically stored tables) and derived relations (views). A view is a named query stored in the database catalog that returns a virtual table.
Example of a base table:
CREATE TABLE S (
SNO CHAR(5),
STATUS INT,
CITY VARCHAR(20),
PRIMARY KEY (SNO)
);
Example of a view:
CREATE VIEW SST_PARIS AS
SELECT SNO, STATUS
FROM S
WHERE CITY = 'Paris';
Views do not store data (unless materialized explicitly by the RDBMS). They provide logical abstraction, simplify queries, and enhance security by limiting data exposure.
5. How Views Are Conceptually “Materialized”
In relational theory, both base tables and views are logical relations. Whether a DBMS physically stores a base table or computes it from other structures is an implementation detail. Oracle, PostgreSQL, SQL Server, and other systems typically store base tables directly, but the relational model itself does not require this.
- Base relations contain stored data.
- Views are computed from base relations and provide alternative perspectives.
SQL vendors choose physical storage strategies that balance performance and data independence. For example, an optimizer might rewrite a view query or substitute precomputed materialized results.
6. Base Relations in Relational Algebra
Base relations are the foundation from which all derived relations originate. They are the permanent data sources used to construct more complex queries and views.
- Physically stored in most SQL products.
- Directly modifiable with INSERT, UPDATE, DELETE.
- Optimized for indexing and constraints.
Examples include Customers, Orders, Products, and Employees.
The next lesson examines the completed data dictionary for the database.