In logical design you decide what data the database stores and how tables relate. In physical design you decide how that data is laid out on disk so that common queries run as quickly and efficiently as possible.
Database clustering in this lesson refers to arranging related rows from one or more tables so they are stored close together in the same set of disk blocks. When the RDBMS can read a group of related rows with a small number of I/O operations, joins and lookups become faster and more predictable, especially for large tables.
Modern RDBMS platforms implement clustering through features such as clustered indexes, table clusters, index-organized tables, and partitioning. The details differ by product, but the goal is the same: align the physical layout of data with real access patterns.
From Contiguous Blocks to Clustered Tables
Earlier in this module you saw that a file stored in contiguous blocks on disk is read more efficiently than the same file scattered across the drive. The same idea applies to tables and joins.
A document stored in contiguous blocks can be read with minimal disk head movement; a fragmented document requires extra I/O.
If tables were always accessed one at a time, you could treat each table like that document and simply keep its rows together. In real workloads, however, tables are frequently joined:
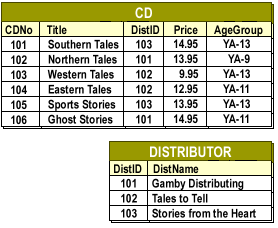
CDs joined to distributors.
Orders joined to customers.
Line items joined to products.
Clustering extends the “contiguous blocks” idea so that rows that are often joined together are stored near each other, reducing the number of blocks the RDBMS must touch during a join.
Joins between these tables are based on DistID, a primary key in DISTRIBUTOR and a foreign key in CD.
During requirements analysis you discover that many queries ask questions such as:
“List all CDs for each distributor.”
“Show CD titles and distributor names together.”
Because DistID drives these joins, it is a good candidate for clustering. A physically clustered layout stores:
Rows from the CD table.
Rows from the DISTRIBUTOR table with matching DistID values.
in the same or neighboring blocks whenever possible. The RDBMS can then satisfy the join with fewer disk reads.
What Clustering Achieves
Clustering is a physical design choice that complements, but does not replace, logical design and indexing. Its purpose is to:
Reduce disk I/O for common joins
When rows that join together are stored together, the RDBMS often reads a single block (or a small set of blocks) instead of visiting many scattered locations.
Improve locality of reference
Queries that scan related rows benefit from having those rows close together. This increases cache hit rates and reduces mechanical movement for spinning disks.
Align storage with access patterns
Clustering forces you to think about real workloads. You choose clustering keys based on business questions, not just on theoretical design.
Provide predictable performance
For high-traffic join patterns, clustering makes performance less sensitive to table growth because the physical layout continues to match query patterns.
Conceptually, clustering says, “If the application frequently looks at these rows together, store them together.”
Clustered Layout for the Example
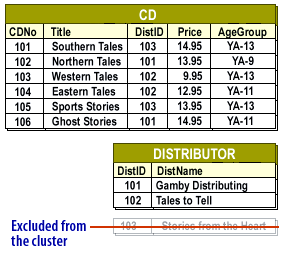
Suppose storage space limits how many rows you can hold in a single block. You might cluster:
The entire CD table.
Only distributors 101 and 102, because they are the ones actually referenced in the CD table.
Distributor 103 still exists in the database, but its row is not colocated in this particular cluster because no CD currently references it.
Distributor 103 still exists in the base table, but is not part of this particular clustered block because no CD row in the block points to it.
When the RDBMS executes a join on CD.DistID = DISTRIBUTOR.DistID, it can satisfy many queries using this single cluster of rows, instead of repeatedly jumping across the disk.
Clustering vs. Other Performance Techniques
Clustering is one of several physical design tools you have:
Indexes efficiently locate rows by key values.
Clustering arranges rows so that related keys live near each other on disk.
Partitioning splits large tables into smaller pieces based on key ranges or hash functions.
Hardware upgrades (faster CPU, more RAM, SSD storage) improve performance regardless of logical or physical design.
The key point for this lesson is that clustering is a layout decision: it changes where rows live physically, not which rows exist logically. Good designs combine:
Sound logical modeling.
Appropriate indexing.
Selective clustering for the most critical join paths.
When Clustering Helps Most
Clustering is most effective when:
Workloads repeatedly join the same tables on the same keys.
Queries scan ranges of related values (for example, “all CDs for this distributor”).
Tables fit into reasonably sized clustered segments so that each segment can be read with a small number of I/O operations.
It is less useful when:
Access patterns are highly random or constantly changing.
Tables are small enough that full scans are already cheap.
Frequent inserts and updates on the clustering key would cause constant reorganization (the tradeoffs for clustering are explored in the next lesson).
As with indexing, clustering should be driven by real query patterns observed during requirements analysis and performance monitoring.
In summary, database clustering in physical design:
Groups related rows in the same or nearby blocks.
Reduces disk I/O for common joins and range queries.
Aligns physical storage with business-driven access patterns.
Works alongside indexing and partitioning as part of an overall performance strategy.
The next lesson examines the performance tradeoffs of clustering, including its impact on inserts, updates, and table growth.