| Lesson 5 | Achieving 1NF |
| Objective | Decompose a table to achieve 1NF. |
Achieving First Normal Form
Goal of 1NF: ensure that each row–column intersection stores a single, indivisible value and that the table has no repeating groups. Doing this makes updates predictable, queries simpler, and constraints enforceable.
Steps to Put a Table into 1NF
- Identify repeating groups. Look for columns like
Author1,Author2or cells storing comma-separated lists. These represent multiple values of the same attribute. - Move the repeaters to their own relation. Create a new table that holds one row per repeated value and relate it back with a key.
- Choose a key. Select a primary key (single column or composite) that uniquely identifies each row.
- Make attributes atomic. Each column should hold one value of its declared type (no embedded lists or structures).
Note: “Partial dependencies” are a Second Normal Form (2NF) concern and are not part of achieving 1NF. We handle those after 1NF is satisfied.
Keys vs. Indexes (Quick Clarification)
- Keys (primary, unique, foreign) are logical constraints that define identity and relationships.
- Indexes are physical access structures used to speed lookups. A primary/unique key is enforced with an index, but the two concepts are not the same.
Books Table Relation

Author1 and Author2. These two columns store multiple occurrences of the same attribute (author) and therefore form a repeating group, which violates 1NF.
Minimal 1NF Fix (One-to-Many Authors per Book)
This decomposition removes the repeating group by giving each author their own row. It matches the diagram that links BOOK to AUTHOR via BookID.
Book (BookID, ISBN, Title, Date, Pages, Publisher, City)
Author (AuthorID, BookID, AuthorName) -- many authors per book
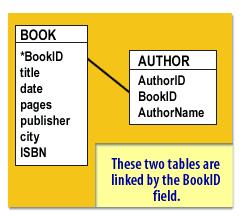
BookID is the primary key in BOOK and a foreign key in AUTHOR. This satisfies 1NF by eliminating the repeating group (Author1, Author2).
General Case (Recommended): Many-to-Many via a Join Table
In many systems an author can write many books, and a book can have many authors. Model that with an associative table:
Book (BookID, ISBN, Title, Date, Pages, Publisher, City)
Author (AuthorID, AuthorName)
BookAuthor (BookID, AuthorID, AuthorOrder) -- preserves contributor order
-- Example query: list authors for each book in the intended order
SELECT b.Title, a.AuthorName
FROM Book b
JOIN BookAuthor ba ON ba.BookID = b.BookID
JOIN Author a ON a.AuthorID = ba.AuthorID
ORDER BY b.BookID, ba.AuthorOrder;
Checklist for 1NF
- No comma-separated values or arrays in a single cell.
- No columns of the form
Thing1,Thing2, … for “more of the same.” - A clear primary key that uniquely identifies each row.
Summary
To normalize to 1NF, (1) find repeating groups, (2) move them into their own relation, and (3) ensure atomic attributes with a stable primary key. Once 1NF is in place, proceed to 2NF to address partial dependencies and then 3NF for transitive dependencies.
Achieving First Normal Form - Exercise
Achieving First Normal Form - Exercise