A database primary key is a column or combination of columns that uniquely identifies each row in a
table. Unique primary keys guarantee unique rows, which makes it possible to address every row in
a table with precision. This is the foundation of entity identification in a relational
database: the ability to retrieve any specific piece of data using exactly three pieces of
information:
The name of the table
The name of the column
The primary key of the row
If primary keys are unique for every row, you are guaranteed to retrieve exactly the row you want.
If they are not unique, you retrieve some row with that key value - which may or may not be the row
containing the data you need. Non-unique primary keys make reliable data retrieval impossible.
Entity Identifier in an ERD vs. Primary Key in a Database Table
The entity identifier in an Entity Relationship Diagram and the primary key in a
database table are closely related but serve different roles at different stages of the database
development process.
Entity Identifier - Conceptual Level
The entity identifier is defined during the design phase of the DBLC, within the ERD. It represents
a unique attribute or combination of attributes that can distinguish each instance of an entity from
every other instance. The entity identifier is an abstract, design-level concept - it describes what
makes an entity instance unique without specifying how that uniqueness will be enforced in the
physical database.
In an ERD for a Customer entity, the entity identifier might be CustomerID if that
attribute is always unique, or a combination of FirstName and LastName
if no single attribute is sufficient for uniqueness. The identifier is typically shown with an
underline or other notation in the ERD to mark its importance.
Primary Key - Physical Level
The primary key is the physical implementation of the entity identifier when the database is
created. It is a concrete constraint defined in the database schema using SQL. Where the entity
identifier is a design decision, the primary key is an enforceable rule built into the table
structure.
A primary key in a database table must satisfy three requirements that the RDBMS enforces
automatically:
Uniqueness - no two rows in the table can share the same primary key value.
Indexed - most RDBMS platforms automatically create an index on the primary
key column to optimize query performance.
The transition from ERD to database implementation maps directly: CustomerID as the
entity identifier in the ERD becomes the PRIMARY KEY constraint on the
CustomerID column in the Customer table. The entity identifier describes the concept;
the primary key enforces it.
The selection of a primary key has lasting consequences for the database's integrity, performance,
and maintainability. A well-chosen primary key has six characteristics:
Uniqueness. The primary key must uniquely identify each record. No two rows
in the table can share the same primary key value. This is the non-negotiable requirement - a
primary key that permits duplicate values is not a primary key.
Non-nullability. Every primary key column must always contain a value. A null
primary key means the row cannot be uniquely identified, which defeats the purpose of the key.
The RDBMS enforces this through the entity integrity constraint.
Stability. Primary key values should not change after they are assigned.
Changing a primary key value requires updating every foreign key in every related table that
references that value - a cascading update that is error-prone and operationally expensive.
A stable key eliminates this risk.
Simplicity. Single-column keys are generally preferable to composite keys.
Simple keys produce simpler JOIN conditions, simpler foreign key references, and simpler
application code.
Sequential. An auto-increment integer primary key - generated by the RDBMS
in sequence - provides predictable ordering, compact storage, and efficient B-tree indexing.
Most RDBMS platforms support this directly: Access uses the AutoNumber data type; Oracle and
PL/SQL use Sequences.
Minimal. The primary key should use the smallest data type that satisfies the
uniqueness requirement. Smaller keys consume less storage, fit more index entries per page, and
produce faster index lookups.
Characteristics of a Bad Primary Key
Understanding what makes a poor primary key is as important as understanding what makes a good one.
Six categories of primary key choice should be avoided:
Non-unique values. A primary key that permits duplicate values is
fundamentally broken. The RDBMS will either reject the duplicates outright or, if no primary
key constraint is defined, silently allow data integrity violations that compound over time.
Sensitive or personal information. Social Security numbers, national
identification numbers, and email addresses are poor primary key choices. SSNs can be
recycled, incorrectly assigned, or changed. The U.S. government strictly limits when SSNs may
be collected and used. Email addresses change when customers change providers. Any key derived
from personally identifiable information also creates privacy and security exposure.
Excessive complexity. Composite keys spanning many columns produce complex
JOIN conditions, lengthy foreign key definitions, and application code that must manage
multiple key values. Where a surrogate key would suffice, a complex composite key adds
overhead without benefit.
Mutable fields. Any attribute that the entity's owner can change - a person's
name, a phone number, a username - makes a poor primary key. Changes to such values require
cascading updates to all referencing foreign keys, which is operationally expensive and
error-prone.
Large data types. Primary keys defined as lengthy VARCHAR strings or binary
values produce large index entries, slower index traversal, and larger foreign key columns in
related tables. An integer key that fits in four bytes is dramatically more efficient than a
UUID string that requires 36 characters.
Meaningful data. An employee ID that encodes department codes, job grade, and
hire year may seem convenient, but it creates a maintenance problem: when the employee changes
departments or job grade, the primary key - which should never change - now carries incorrect
meaning. Surrogate keys store no meaning and therefore never become stale.
Rules for Designating a Primary Key
Along with uniqueness, a primary key must not contain the value null. Null is a special database
value meaning "unknown" - it is not a zero or a blank. A single row with a null primary key cannot
be uniquely identified. Two rows with null primary keys immediately violate uniqueness, since null
equals null in terms of constraint evaluation. The constraint that forbids null values in primary
key columns is called entity integrity. Every RDBMS enforces entity integrity automatically whenever data is inserted or modified.
Identification of primary keys is a central task in entity type identification. Primary keys should
be:
Stable - a primary key should never change after it has been assigned to an
entity instance. The key is the anchor by which all other systems and tables reference that
row; changing it severs those references.
Single purpose - a primary key attribute should have no purpose other than
entity
identification. It should carry no business meaning that could become incorrect over time.
The best choices for primary keys are integer values automatically generated by the RDBMS.
Access uses the AutoNumber data type; Oracle and PL/SQL use Sequences. Both produce stable,
unique, sequential, minimal integer keys with no business meaning - exactly what a primary key
should be.
In ER diagrams, primary key fields are typically marked with an asterisk (*). Some RDBMS tools
underline the key field name or render it in bold. In the new image-based notation used in this
course, the primary key row is highlighted with a key icon and a distinct background color.
Additional Guidelines: Avoid External Identifiers
A primary key should never be a value that originates or is used outside the database. Two common
violations:
Social Security numbers (Social Insurance Numbers in Canada) - these can be
recycled, incorrectly assigned, or legitimately changed. The U.S. government strictly limits
when SSNs may be collected and used, making them legally problematic as database identifiers
in many contexts.
License plate numbers - an owner can request personalized plates, and a state
may renumber its entire plate system to accommodate population growth. Either event changes the
value, violating the stability requirement.
The better practice is to create a surrogate key - a system-generated unique identifier that
represents each row and stores no meaningful data. The surrogate key is owned by the database,
not by the external world, and therefore cannot be changed by external events.
Candidate Keys
A candidate key is a field or combination of fields that can act as a primary key -
uniquely identifying each record in a table. A table may have multiple candidate keys, but only one
is designated as the primary key. The others become alternate keys and should be enforced with
UNIQUE constraints.
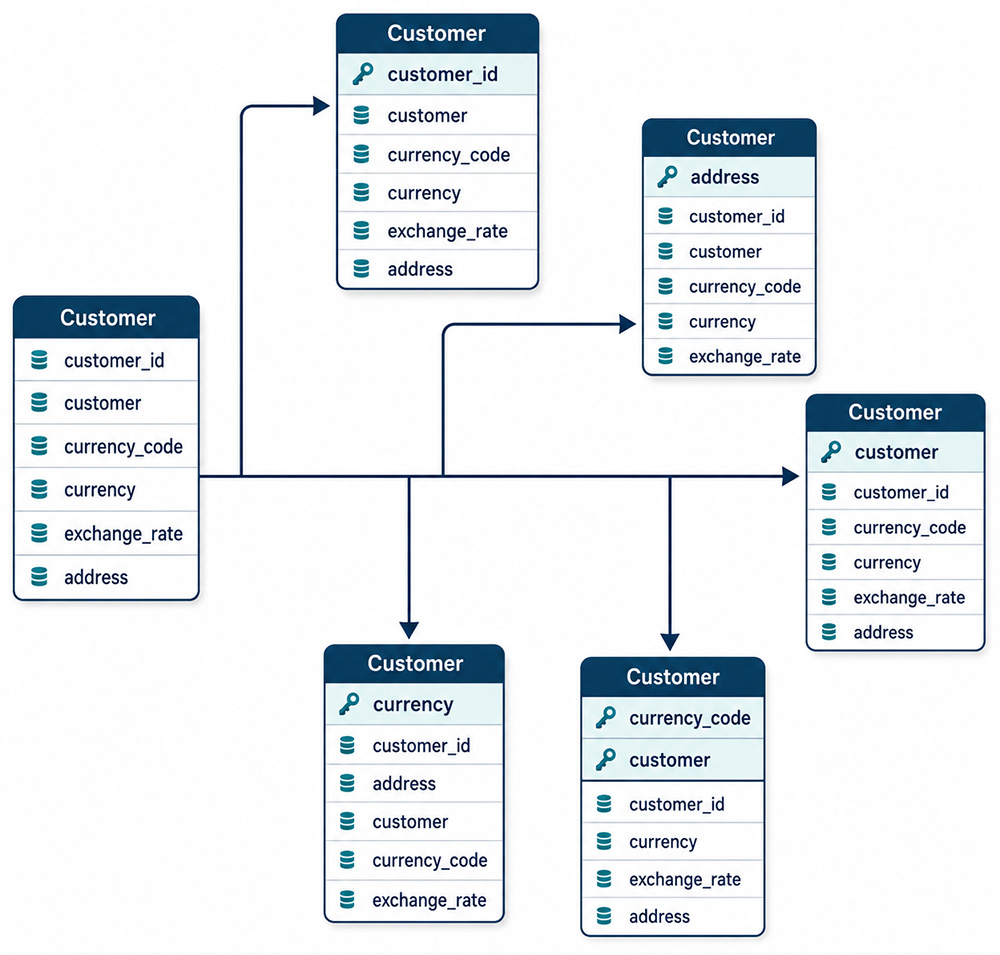
Figure 2-11 illustrates five variations of the Customer table, each showing a different candidate
key. The Customer table contains six attributes: customer_id, customer,
currency_code, currency, exchange_rate, and
address.
Figure 2-11 shows five variations of the Customer table, each with a different candidate key
highlighted by a key icon and light blue background. The five variations demonstrate which
attributes could theoretically serve as primary keys and why most of them fail the stability
and uniqueness requirements:
customer_id (top-center) - a surrogate integer key with no business
meaning. Unique, stable, non-null, and system-generated. This is the correct choice for
a primary key.
address (top-right) - a customer's address could theoretically be unique,
but addresses change when customers move, violating the stability requirement.
customer (right) - the customer's name is not reliably unique (two
customers can share a name) and names change through marriage or legal name change,
violating both uniqueness and stability.
currency (bottom-center) - the currency name (e.g., "US Dollar") is
shared by many customers and therefore fails the uniqueness requirement entirely.
currency_code + customer (bottom-right) - this variation shows two key
icons, indicating a composite candidate key. Neither currency_code
nor customer alone is unique, but together they might be. However, this
composite key still fails the stability requirement (names change) and the simplicity
requirement (composite keys are more complex than surrogate keys). It does demonstrate
that candidate keys can span multiple columns.
Figure 2-11: A Customer table with five candidate key variations.
The License Plate Candidate Key Example
A car's license plate number is a classic example of a candidate key that fails to qualify as a
primary key:
Within a single state, each license plate number is unique, so PlateNo alone
could serve as a candidate key for a state-level vehicle database.
In a nationwide vehicle database, the same plate number can exist in multiple states.
The combination of State and PlateNo forms a composite candidate key that is unique
nationwide.
The problem is stability. License plate numbers change in two common scenarios:
The vehicle owner requests a personalized plate with a custom message.
The state redesigns its numbering system to accommodate more registered vehicles.
In either case, the plate number associated with a specific car changes - which would require
updating the primary key and cascading that change to every table that references it. This is
exactly the kind of instability that makes a candidate key unsuitable as a primary key.
When evaluating a candidate key for promotion to primary key, apply two tests:
The value cannot change after assignment.
The column cannot contain a null value.
If the candidate key satisfies both requirements, it qualifies as a primary key. If it fails
either, look for a different candidate or introduce a surrogate key.
The next lesson defines concatenated primary keys[1].
[1]Concatenated primary key: A primary key made up of more than one
field. Also called a composite primary key.