Surrogate keys are almost never defined in the logical model. They either do not map to
real data elements or are derivable from other data - both of which are reasons to exclude them
from the logical design. Surrogate keys only enter the picture when the physical model is being
designed, at which point they become an additional class of candidate key to consider.
Three types of surrogate keys exist:
Concatenated surrogate keys[1] - compressed,
multicolumn data strings that combine existing columns into a single key value.
Semisurrogate keys - replace a portion of a multicolumn key with a system-generated
number, keeping some natural data in the key while reducing its complexity.
Surrogate keys - completely system generated; the key value has no relationship to
the data in the row and is produced entirely by the RDBMS.
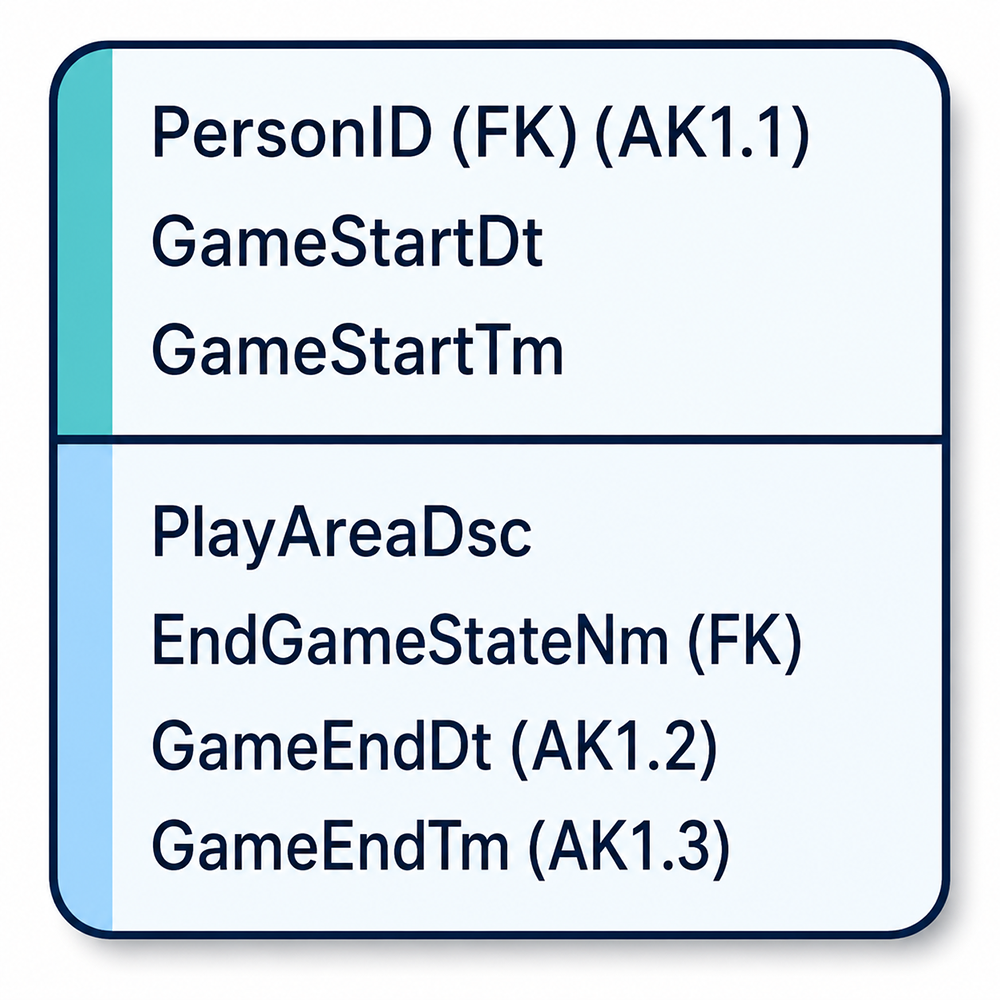
The GAME table provides a practical context for evaluating these choices. Figure 2-12 shows the
logical structure of the GAME table with its attributes and alternate key notation.
Figure 2-12: Choosing the primary key of Game. The GAME table shows a composite alternate key
(AK1) spanning three columns: PersonID (AK1.1), GameEndDt (AK1.2), and GameEndTm (AK1.3).
No single column serves as a natural primary key.
The AK1 notation in Figure 2-12 identifies an Alternate Key: a composite key made up of three
columns - PersonID (AK1.1), GameEndDt (AK1.2), and GameEndTm (AK1.3). Together these three
columns could uniquely identify each game record. Table 2-13 shows sample data that illustrates
why.
Table 2-13: Instance Table for Game. Person 1 played two games on the same date at the same
play area. PersonID alone cannot serve as the primary key because it is not unique across rows.
Ruling Out the Natural Key as Primary Key
The instance table in Table 2-13 shows that Person 1 played two games on the same day at the same
play area - winning one and losing one. Examining sample data often clarifies primary key choices
that logical modeling left ambiguous. In this case, the data confirms that no natural single-column
key exists: PersonID repeats across rows, and the play area and date repeat as well.
The only natural key candidate is the composite of PersonID, GameEndDt, and GameEndTm. Each game
ends at a different time, so this combination is unique for each row. However, experience with
physical database design argues against using this composite as the primary key. Dates and times
in a primary key introduce two practical problems:
RDBMS platforms format date and time data in platform-specific ways. A primary key composed
of date and time values can behave differently across platforms, complicating portability and
migration.
Using date and time values as primary key components makes the key awkward to use
programmatically. Application code that constructs queries using a three-part temporal key
is more complex and more error-prone than code using a single integer key.
For these reasons, the natural composite key is ruled out as the primary key for the GAME table.
This brings surrogate keys into consideration.
Surrogate Keys: System-Assigned Keys
Surrogate keys are also known as System-Assigned Keys (SAKs). The implementation is
straightforward: the system generates a unique number each time a record is inserted into the
table, and that number becomes the primary key. The generated value carries no business meaning -
it exists solely to identify the row.
One important rule when using surrogate keys: place a unique index on at least one natural key to
prevent inadvertently duplicating rows. The surrogate key guarantees that each row has a unique
identifier, but it does nothing to prevent two rows from representing the same real-world event
with different surrogate key values. The unique index on the natural key is the guard against
that problem.
Surrogate keys offer real advantages in physical database design:
Numeric keys are faster to sort and index than text or composite keys.
A single-column integer key is simpler to use in JOIN conditions and foreign key references
than a three-column composite key.
For large tables where performance is a concern, the compactness and sort efficiency of a
numeric surrogate key can make a measurable difference.
However, surrogate keys should never be applied as a default design choice. The warning is worth
stating explicitly: surrogate keys are frequently used as the primary key for every table without
any consideration of what other choices might be made. This habit promotes a narrow view of
database design and a lack of concern about the quality and meaning of the data. A surrogate key
is a tool to be chosen deliberately when other options are unsuitable - not a default to be applied
without thought.
Guidelines for Using Surrogate Keys
Choosing to use a surrogate key requires addressing several implementation issues that do not arise
with natural keys:
Natural key enforcement. A surrogate key has no meaning outside the database.
To fulfill the full purpose of a primary key - ensuring that the table contains no duplicate
real-world entities - you must enforce uniqueness on at least one natural key through a unique
index or unique constraint. Without this, the surrogate key prevents duplicate key values but
does not prevent duplicate data.
Concurrency. When multiple transactions simultaneously insert rows into a
table, the RDBMS must assign unique surrogate key values to each row without conflict. The
mechanism for handling concurrent key generation varies by platform and must be verified before
committing to a surrogate key design.
Reusability. Whether surrogate key values can be reused after rows are deleted
affects database design in multi-table systems. Oracle and DB2 UDB address this through
sequence generator structures that are independent of individual tables, allowing sequences to
be shared and configured for reuse or non-reuse. In SQL Server, the identity column
specification is table-specific, which makes reusing identity values across different tables
difficult. Verify how your target RDBMS handles key reusability before finalizing the design.
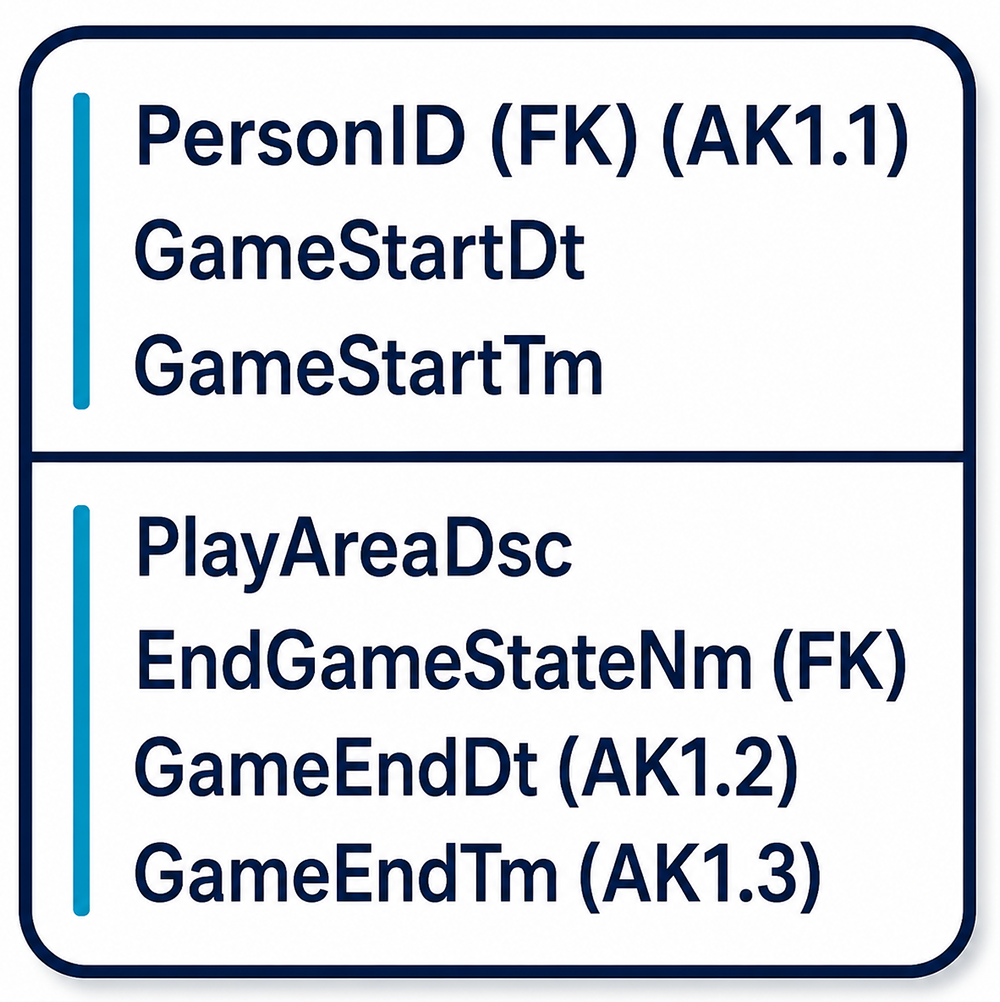
Figure 2-18 shows the GAME table redesigned with a surrogate key. The structure is identical to
the concatenated key version except that the three-column composite key (PersonID + GameEndDt +
GameEndTm) has been replaced by a single system-generated GameID integer. The result is simpler,
faster, and easier to use in application code.
Figure 2-18: Choosing to use a surrogate key as the primary key of Game. The GameID surrogate
key replaces the three-column natural key, producing a simpler and more efficient primary key
while the natural key attributes remain available for unique index enforcement.
Preventing Duplicate Values Without a Surrogate Key
When a surrogate key is not the right choice, five techniques enforce uniqueness directly on
natural data:
Unique Constraints. A UNIQUE constraint on one or more columns prevents any
two rows from sharing the same value in those columns. This is the most direct mechanism for
enforcing natural key uniqueness. For example, a UNIQUE constraint on an Email column ensures
that no two user records share the same email address, regardless of whether a surrogate key
is used as the primary key.
Primary Key on Natural Data. When natural data columns are inherently unique
and stable, define the primary key directly on those columns. A combination of FirstName,
LastName, and BirthDate might uniquely identify employees in a specific organizational context.
Composite Unique Index. When no single column is unique but a combination is,
a composite unique index enforces that combination without requiring it to be the primary key.
This allows a surrogate key to remain as the primary key while natural uniqueness is still
enforced.
CREATE UNIQUE INDEX idx_person_unique
ON Persons (FirstName, LastName, BirthDate);
Check Constraints. CHECK constraints enforce format and value conditions that
indirectly reduce the likelihood of certain classes of duplicates. Requiring that order numbers
follow a specific format prevents free-form entries that could generate ambiguous duplicates.
Trigger-Based Validation. For complex uniqueness requirements that constraints
cannot express, database triggers run custom logic before INSERT or UPDATE operations. The
trigger checks for existing rows that match the incoming data and rejects the operation if a
duplicate would result.
CREATE TRIGGER CheckDuplicateBeforeInsert
BEFORE INSERT ON Employees
FOR EACH ROW
BEGIN
DECLARE duplicate_count INT;
SELECT COUNT(*) INTO duplicate_count
FROM Employees
WHERE FirstName = NEW.FirstName
AND LastName = NEW.LastName
AND BirthDate = NEW.BirthDate;
IF duplicate_count > 0 THEN
SIGNAL SQLSTATE '45000'
SET MESSAGE_TEXT = 'Duplicate employee cannot be added';
END IF;
END;
Each of these techniques enforces data integrity without relying on a surrogate key. In many
designs, one or more of them will be used alongside a surrogate key to enforce natural uniqueness
while still benefiting from the performance and simplicity of a system-generated primary key.
The next lesson discusses foreign keys.
[1]Concatenated surrogate key: A primary key created by combining two
or more existing columns to form a unique identifier for each row. Also called a composite key.