Explain the purpose of Database Table Partitioning
Database Table Partitioning in Physical Design
Logical design focuses on what data the database stores. Physical design focuses on how that data is laid out on disk so real workloads run efficiently. Table partitioning sits squarely in this physical design layer.
Where clustering brings together related rows from different tables, partitioning splits a single large table into smaller, more manageable pieces. The goal is simple:
Reduce the amount of data the RDBMS must scan for common queries.
Isolate “hot” data from “cold” data for better performance and maintenance.
Support backup, archiving, and lifecycle management at a chunk level instead of whole-table level.
Partitioning is especially useful for very large tables whose rows or columns are not accessed uniformly. In this lesson you will see why table partitioning improves performance and how horizontal and vertical partitioning support different access patterns.
Purpose of Table Partitioning
As a database grows, some tables can reach millions or billions of rows. Even with good indexing, full-table scans, maintenance operations, and backups can become slow and resource intensive. Table partitioning addresses these problems by:
Reducing I/O for common queries
If a query only needs “recent orders” or “active customers,” there is no reason for the RDBMS to scan old history. Partitioning allows the optimizer to scan only the relevant partitions, a feature often called partition pruning.
Separating data by lifecycle
Operational data and historical data often have very different access patterns and retention requirements. Partitioning lets you keep current data in fast storage and archive older partitions without touching the rest of the table.
Simplifying maintenance
Operations such as index rebuilds, statistics gathering, and backups can be performed at the partition level. This “divide and conquer” approach reduces lock contention and maintenance windows.
Supporting scalability
In modern RDBMSs, partitioning is a key building block for very large tables, distributed storage, and parallel query execution.
At a conceptual level, partitioning lets you keep the logical view of “one table” while implementing it as multiple physical segments optimized for performance and manageability.
Horizontal Partitioning
Horizontal partitioning splits a table by rows. Each partition has the same columns but contains a different subset of rows based on a rule, such as:
Date ranges (one partition per month or year).
Geographic regions (one partition per region).
Status (open versus closed orders).
Conceptually, you are “drawing a horizontal line” through the table and dividing the rows into multiple range, list, or hash-based partitions.
For example, a growing order system might separate open and filled orders:
Most queries and updates hit the open_* tables, which remain relatively small. Historical reports query the filled_* tables, which can be much larger and slower without affecting day-to-day operations.
When all items in an order ship, an application process moves the corresponding rows from the “open” partitions into the “filled” partitions. That movement keeps the hot partitions small and focused.
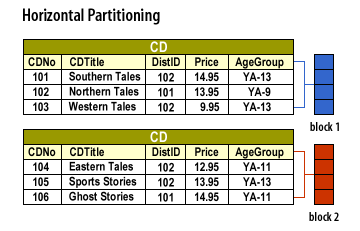
The CD example illustrates the same concept:
CD — Block 1 (Horizontal Partition 1)
Horizontal partitioning splits rows between two identically structured segments. Queries that only need rows from one segment read fewer pages and complete faster.
Horizontal partitioning makes the most sense when:
A subset of rows (for example, current year) is accessed much more frequently than the rest.
Retention and archive policies differ across time ranges or categories.
Large table scans can be restricted to a small set of partitions.
One trade-off: queries that must see all rows across all partitions require the RDBMS to read each partition and logically combine results, often using the union operator[1] or an equivalent partitioned access path.
Vertical Partitioning
Vertical partitioning splits a table by columns. Each partition:
Contains the primary key plus a subset of the original columns.
Stores all rows for those columns.
This approach is helpful when:
A small group of frequently accessed columns accounts for most queries.
Other columns are large, rarely used, or expensive to read (for example, descriptions, JSON, or BLOBs).
For example, an item table might be partitioned as:
Queries that only need title and price can scan a compact, cache-friendly table, while less frequently used attributes live in a separate partition that is joined only when required.
The CD example shows this pattern:
CD — Block 1 (Vertical Partition 1)
Vertical partitioning keeps frequently read attributes in a narrow table while less frequently used or larger attributes reside in a companion table. Both tables share the same primary key so they can be joined when needed.
Vertical partitioning is most effective when access patterns are highly skewed toward a small set of columns. Because queries that need columns from both partitions must perform a join, this design is usually reserved for very wide tables or tables with large infrequently used columns.
Best Practices for Table Partitioning
Modern RDBMSs support range, list, hash, and composite partitioning schemes. Regardless of platform, some general guidelines apply:
Let workload drive partition strategy
Use real query logs and requirements analysis to identify:
Natural boundaries for horizontal partitions (for example, order date, region, tenant).
Columns that are frequently read together versus those that are rarely accessed.
Avoid over-partitioning
Too many tiny partitions can increase planning overhead, complicate statistics, and make maintenance harder. Choose partition sizes that balance manageability and performance.
Align indexes with partitions
Where supported, consider local (per-partition) indexes for common access paths. This keeps index maintenance focused on the partitions that actually change.
Use partitioning for lifecycle management
Dropping or archiving an old partition is far cheaper than deleting millions of individual rows. Partition boundaries that match retention rules simplify compliance and housekeeping.
Measure impact
Always validate partitioning decisions with execution plans and performance tests in a non-production environment. Partitioning that helps one workload may hurt another.
Table partitioning is a powerful physical design tool. Used thoughtfully, it can make large tables easier to query, easier to maintain, and easier to scale.
[1]union operator: The union operation creates one table by merging the rows of two tables with the same structure.